图片隐写题目
1、a_good_idea
先010editor看,右栏Ascii很容易就看到很多misc,to_do.png之类的,binwalk分离得到压缩包,两张一模一样的图片和一个提示文档对像素进行操作。stegsolve里面,进行combine但是什么都看不出来,两个图片互换位置也都试过了。然后上网看了别人的wp之后才知道XOR之后,把曝光调到最后,得到一张二维码。这个想法,所以我想记录一下。
[图像]->[调整]->[曝光度]
2、Training-Stegano-1
拿到图片,丢入010editor
大道至简,这题的flag就是steganoI,不需要套flag{},记录这题想告诉我自己不要想太多吧,这题已经说了passwd: 了
3、pure_color
首先题目名字color有关,拿到图片是一张纯白得图片,很容易想到LSB
但是图片看起来只有半截,先爆破了一下宽高,发现没有问题,在试试LSB
什么也没有只拿到了Adobe ImageReady,猜测和ps有关,搜了一下
打开PS
[图像]->[自动色调]
即可得到flag
4、stage1
丢进stegsolve里,很容易就发现二维码
但是实在Random colour map通道里的,能不能出现,全看运气,我弄了好久才出现一两次,每次你往左一次,再往右,出现的图片颜色不一样了。
十六进制转文件
复制到txt文件,导入010editor,导出为pyc文件
pyc文件反汇编
pip install uncompyle #安装反汇编模块
uncompyle6 1.pyc > 111.py
拿到flag是AlphaLab
5、buu-LSB
题目提示很明显,LSB,不过这一题是将一张图片藏起来了
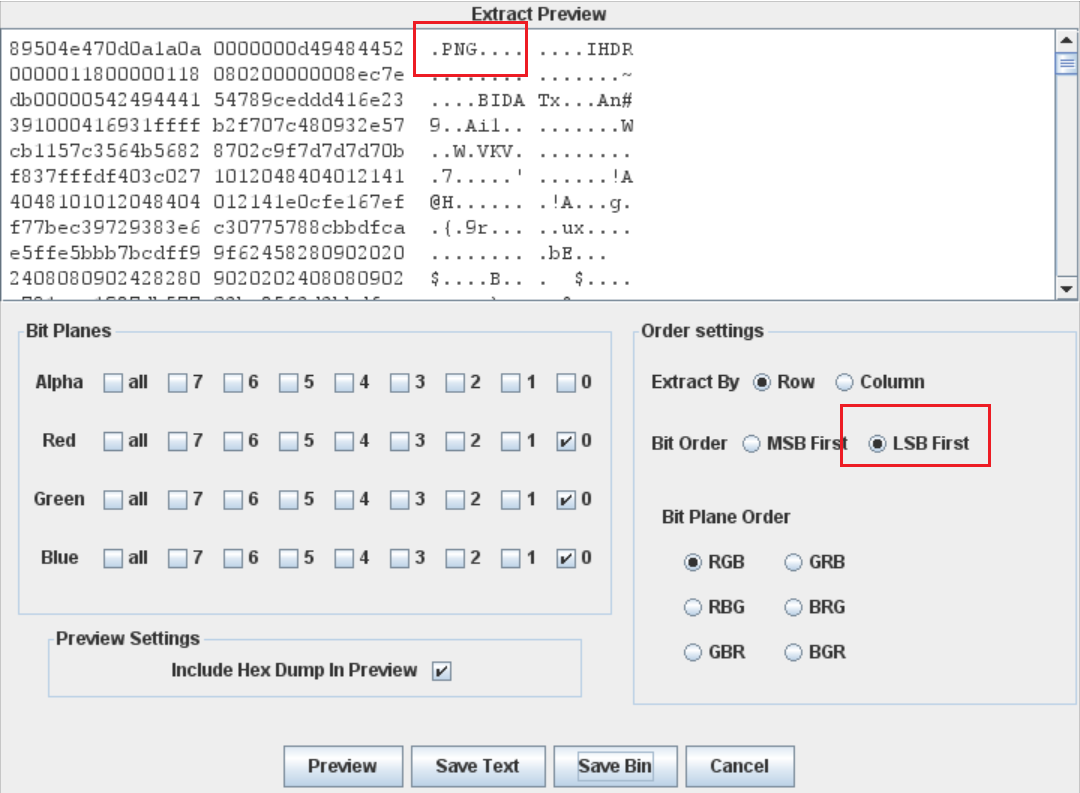
Save Bin为一张图片即可
6、攻防世界-low
题目给了一张黑白的bmp图片

我一直对010editor这种奇怪的东西,表示怀疑,但是好像每次又和解题没什么关系
在zsteg里面看到了这个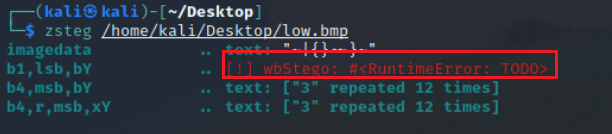
所以我就觉得是wbstego隐写,还挺开心,一想确实啊,webstego可以隐写bmp
但是实则不是,这一题是lsb隐写,bmp文件名给了提示low
是要写脚本的lsb,我看别人的wp才知道
1 | |
得到一张二维码
7、ctfshow-misc4
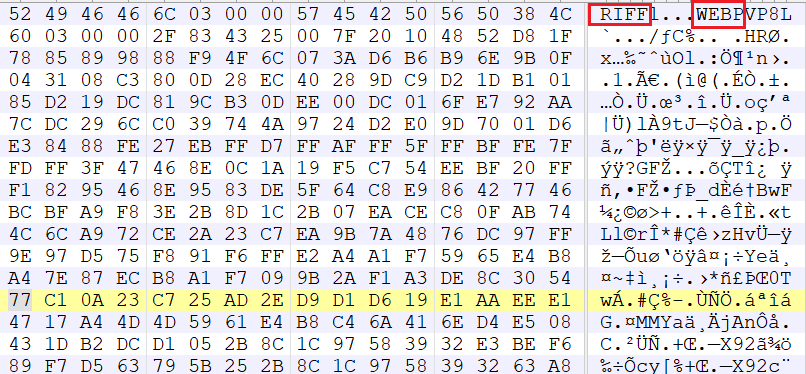
RIFF:(Resource Interchange File Format) 资源互换文件格式,是一种把资料储存在被标记的区块(tagged chunks) 中的档案格式 (meta-format)。RIFF 文件是 windows 环境下大部分多媒体文件遵循的一种文件结构,RIFF 文件所包含的数据类型由该文件的扩展名来标识,能以 RIFF 文件存储的数据包括:音频视频交错格式数据 (.AVI),波形格式数据 (.WAV),位图格式数据 (.RDI), MIDI 格式数据(.RMI),调色板格式 (.PAL),多媒体电影 (.RMN),动画光标 (.ANI) 和其它RIFF文件 (.BND)
将后缀名改为.webp即可看到图片(其实只要是图片格式的jpg、webp、gif之类的,改成png都是可以直接看到图片内容的)
8、ctfshow-九阴真经

不知道是不是stegdetect不准还是咋的
用JPHS解不出来,试了试密码也不知道
(在不知道密码的情况不可以尝试Stegdetect工具里的Stegbreak程序进行基于字典的暴力攻击)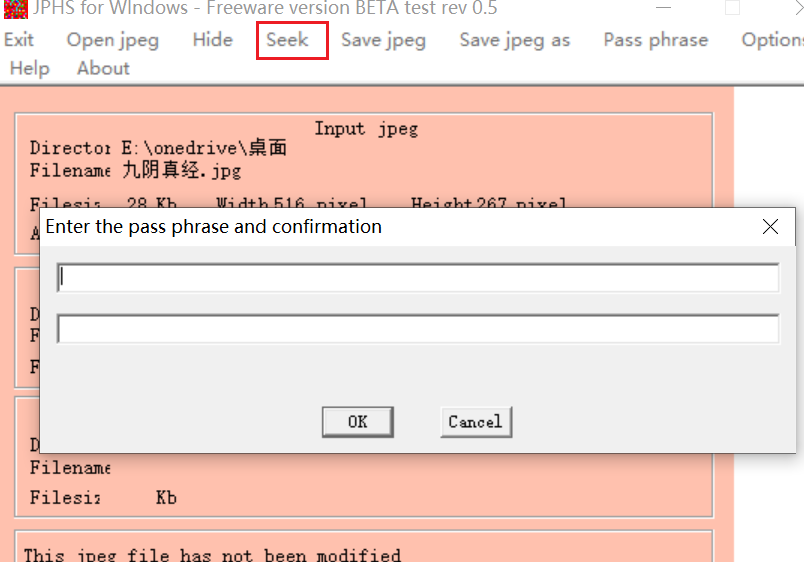
然后呢,这一题的正确写法其实和上面无关
打开010editor,一定要带template,这个功能太好用了(如果你的不带template可以下载一个新版的010editor)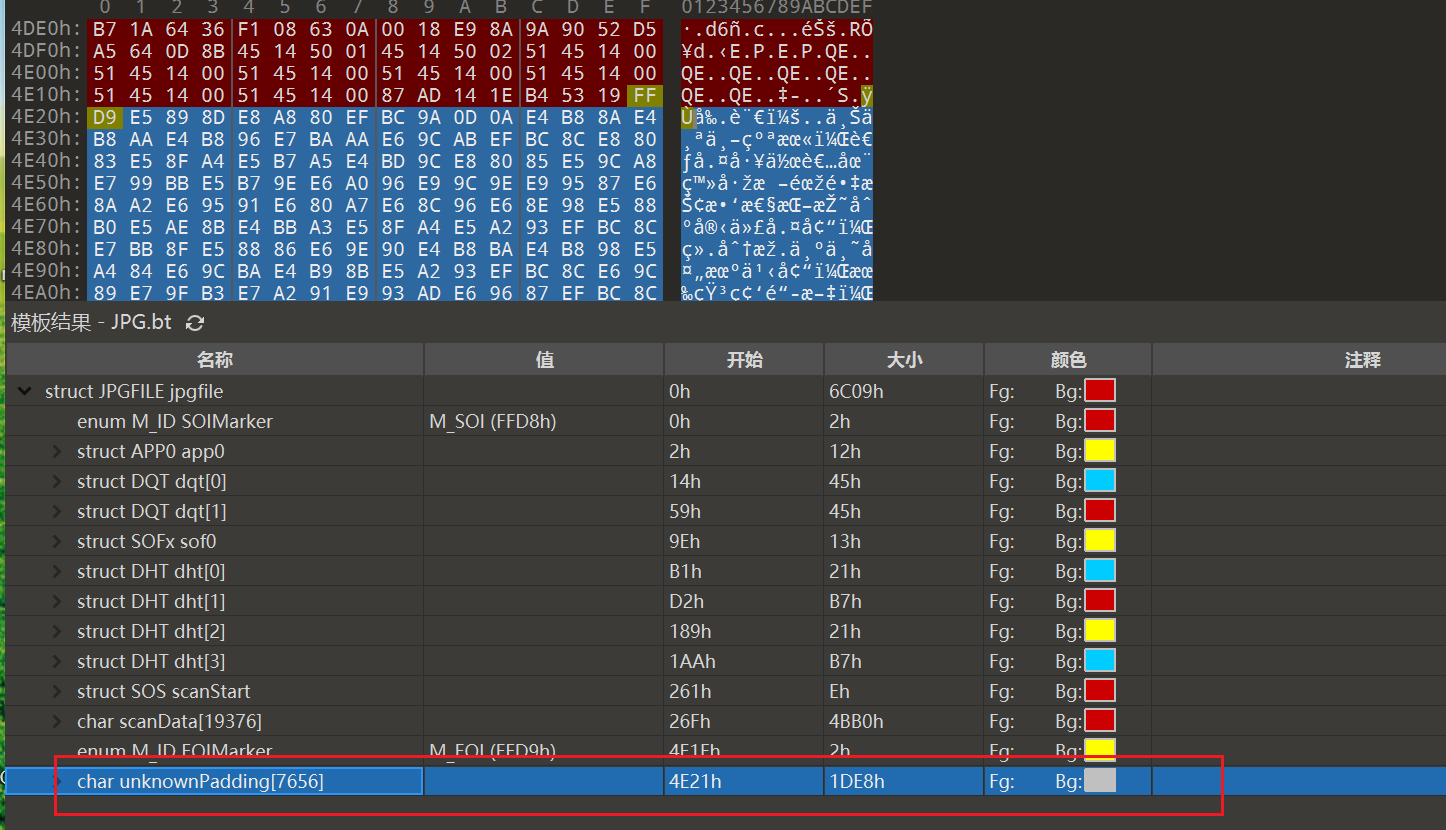
导出为tet文档
发现了什么,把文本中数字提取出来,就是flag了
1 | |
这个脚本自己写的很烂
首先为什么不with open呢
因为with open导进来就变成字节了,然后感觉就有点麻烦
接着
代码第二部分,长十进制转字符,写的有问题,但是能跑起来(之前看到一个写的挺好的,但是没有保存起来)